About cloud-optimised formats
Introduction
In this section, we will dive into cloud-optimised geospatial formats. We explore why these new formats are important and will introduce you to two common cloud-optimised data formats specifically for raster files.
What we will learn
- ☁️ What do we need to cloud-optimise geospatial data?
- 🏛️ Differences between traditional and cloud-native workflows
- 📖 What are the main characteristics of cloud-optimised formats?
- 💾 What are COGs and Zarr, and how do they differ?
Why to cloud-optimise geospatial data formats?
The volume of EO data has grown exponentially in recent years. The Copernicus programme alone generates ~16TB daily from the Sentinel missions. Traditional file formats, like .SAFE (where each file can be hundreds of megabytes), are optimised for efficient archiving and distributing data. This means that we often download the data from an entire overpass, even if we only need to access a small part of it. For example, if we want to do an analysis of the area of a single city over a decade.
With growing data volumes, this becomes a challenge. To picture the different nature of challenges we come across, let us compare a traditional local workflow with a cloud-based workflow:
Traditional local workflow: When working locally, we download much more data than we need, and we are constrained by the compute and storage capacity of the local system. However, an advantage of working locally is that data and compute are close together, meaning that there is not much delay in accessing the data.
Cloud-based workflow: Cloud environments overcome the limitations local workflows have. A cloud environment offers limitless storage and compute capacity. On the contrary, data storage, compute, and you the destination are far apart. There is an additional time for data to travel between the storage location, processing resources and us. This time is referred to as data latency.
Data latency refers to the time it takes for data to be transmitted or processed from cloud storage to your computer. In local workflows, data latency is minimal, whereas in cloud-based workflows, data latency needs to be optimised.
Analogy: Comparing local and cloud-based workflows with ordering a pizza
To understand the principal concept, let us compare local and cloud-based workflows with ordering a pizza. Local workflows are similar to placing an order at a pizza store on your street. It is quick since the data (pizza) is easily accessible, but we can only choose from what the local pizza store offers.
On the other hand, cloud-based workflows are comparable to ordering a pizza from a pizza store in a different city or even country. This option allows you to order different types of pizzas, which are not available in the pizza store on your street. While we might have more options to choose from, the time between order and delivery can become a challenge. The time until your pizza from a different town or country arrives at your house is called data latency.
Hence, the overall goal with cloud-based workflows is to minimise data latency as much as possible. This is why traditional data formats need to be cloud-optimised.
Characteristics of cloud-optimised formats
Cloud-optimised formats are optimised to minimise data latency. By allowing for an efficient retrieval of smaller, specific chunks of information rather than downloading an entire file. Accessing a smaller data subset also reduces the costs associated with data transfer and data processing.
Cloud-optimised geospatial data formats have the following characteristics:
- Data is accessible over an HTTP protocol.
- Read-Oriented, as it supports partial and parallel reads.
- Data is organised in internal groupings (such as chunks, tiles, shards) for efficient subsetting, distributed processing and data access in memory.
- Metadata can be accessed in one read.
When accessing data over the internet (e.g. through object stores in the cloud), latency is high compared to local storage, so it is recommended to fetch lots of data in fewer reads.
Cloud-Optimised Geospatial Raster Formats
For satellite data, two main cloud-optimised formats are being used:
- Cloud-Optimised GeoTIFF (COG): Optimised for 2D image data and originates from the traditional
GeoTIFFformat, and - Zarr: Used and designed for complex, n-dimensional data structures and originates from the traditional formats
netCDFandHDF5.
Cloud-optimised GeoTIFF (COG)
COGs have been widely used as a cloud-native format for satellite imagery and improve the standard GeoTIFF format by:
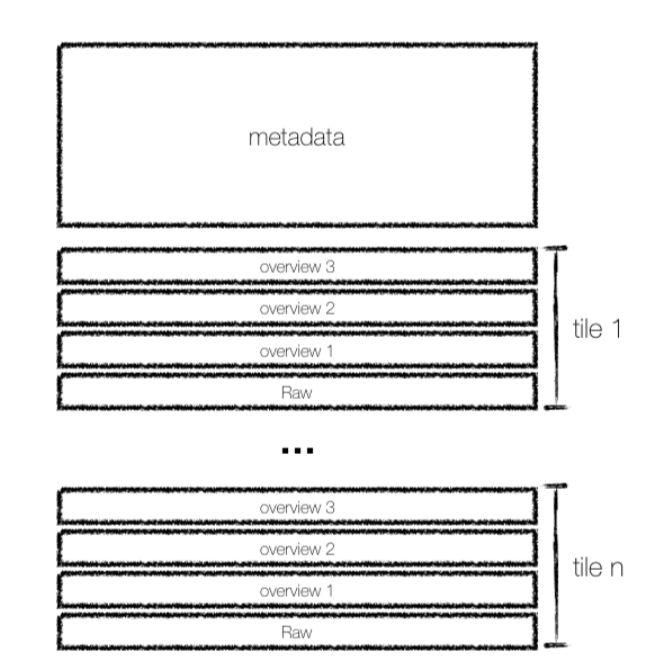
- Organising data into tiles: Dividing the data into smaller, manageable squares (like 512x512 pixels).
- Including lower-resolution previews: Having pre-generated, less detailed versions of the data. This allows for fast and efficient data visualisations.
A key feature of COGs is the Internal File Directory (IFD), which acts like an internal index. This allows for retrieving only the parts of the data needed using simple web requests. For example, it is possible to access just the tiles covering Paris from a large Sentinel-2 image of Europe.
Multi-dimensional Array Storage with Zarr
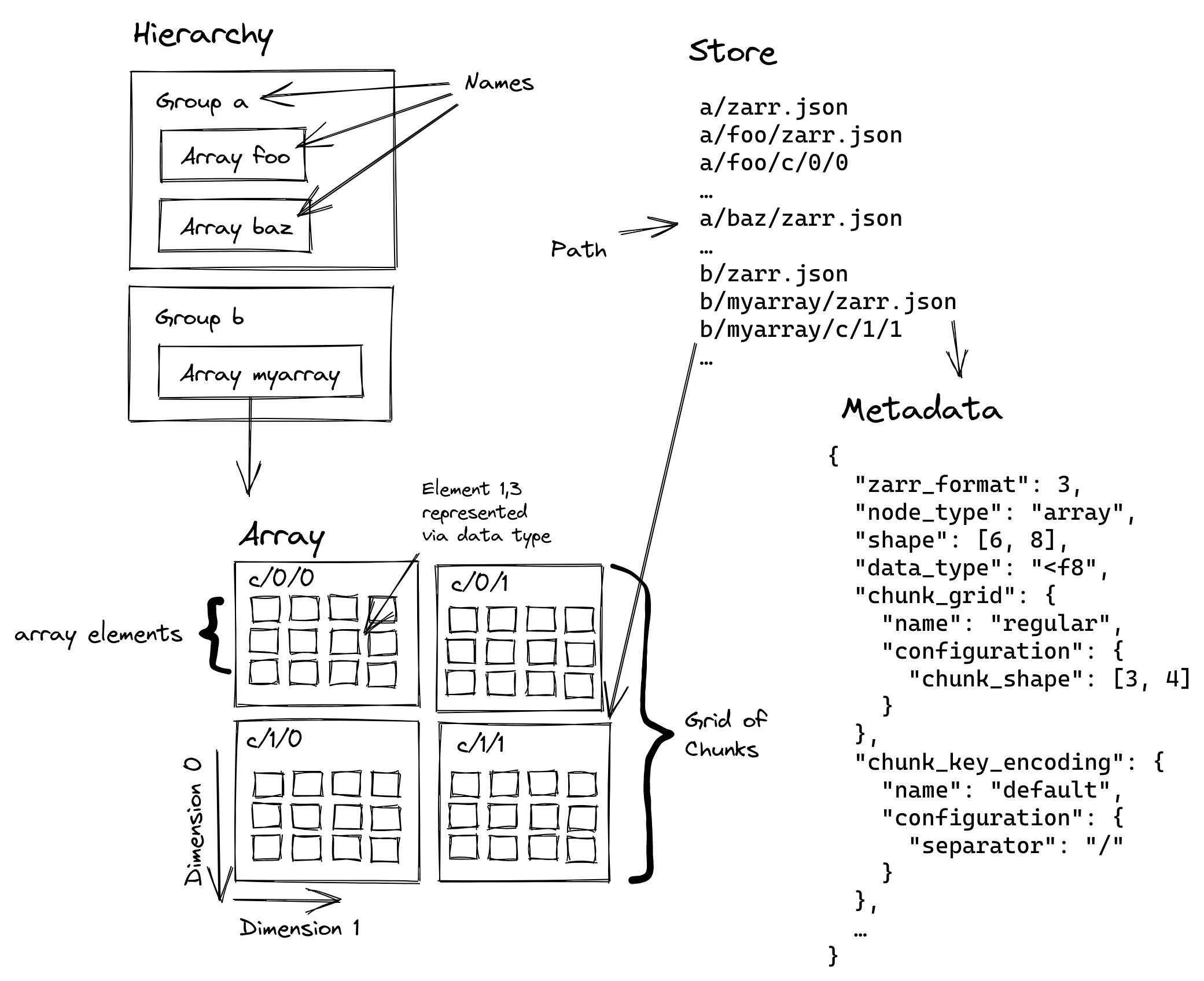
Zarr is the cloud-optimised version for the traditional formats netCDF and HDF5, and is specifically designed for storing and accessing large n-dimensional arrays in the cloud by:
- Chunking: Breaking large arrays into smaller pieces that can be accessed independently
- Compression: Each chunk can be compressed individually for efficient storage
- Hierarchical Organisation: Arrays are organised in groups, similar to folders in a filesystem
- Cloud-Native Access: Optimised for reading partial data over HTTP
- Parallel I/O: Multiple chunks can be read or written simultaneously
- Self-Description: Rich metadata is stored alongside the data using JSON
This makes Zarr particularly well-suited as a storage format for processing Earth observation data in the cloud.
When to use COG versus Zarr?
The table below compares some features of COG and Zarr:
| Feature | Zarr | COG |
|---|---|---|
| Structure | Multi-file chunks | Single file |
| Access | Parallel | Sequential |
| Compression | Differently per-chunk | Whole-file |
| Scales | Multi-scale in single file | Separate, pre-generated lower-resolution files |
Based on the structure and capabilities for each format, COGs are used when:
- You work with two-dimensional raster data (like satellite images or elevation models)
- You need to easily visualise or access specific geographic areas without loading the entire dataset.
- Interoperability with existing GIS software is important, as COG is a widely adopted standard.
On the other hand, Zarr is more often used when:
- You deal with large, multi-dimensional datasets that might be updated or modified.
- You are performing complex analyses that involve accessing different parts of the data in parallel.
- An efficient handling of different resolutions or variables within a single dataset is required.
Zarr vs COG: Want to learn more about the differences and similarities of COG and Zarr? Then we recommend the following blog post by Julia Signell and Jarrett Keifer from Element84, where they discuss “Is Zarr the new COG?”
Conclusion
In this section, we explored the fundamental concepts of cloud-optimised geospatial formats. By understanding the core characteristics of these formats and by looking at specific examples like Zarr, you now have a solid foundation for appreciating how these innovations are making geospatial data more accessible, efficient, and powerful in the cloud.
What’s next?
Now that we have an idea of the available cloud-optimised formats for satellite imagery and the reason why we need to optimise traditional formats for the cloud, in the next section, we will explore the EOPF data products that are being re-processed as part of the EOPF Zarr Sample Service.